Reading Time: 1 minutes

こんにちは、ManageEngineエンジニアもどきの園部です。
もうすぐクリスマスや年末年始のシーズンですね!お休みの計画は立てましたか?
……え?クリスマスも年末年始も仕事?
担当のシステムやネットワークに問題が起きたら呼び出されるから休んでいる気がしない??
・・・(´・ω・`)
大事な休日をゆっくりと過ごすため、ネットワーク管理の自動化を始めてみませんか?
というわけで、今回は、IT運用管理の自動化について考えてみたいと思います。
目次 |
まずは通常業務の自動化
(何故こんなことまで自分がやらなくてはいけないのか……)
(今日もやりたかった仕事に手が付けられなかった……)
日々同じことを繰り返すだけの作業に対して、そう思ったことはありませんか?
しかしそのような業務は、大抵の場合、必須とされていることが多いのではないでしょうか。
また、個人の采配で勝手にやめられないものが大半であると思います。
自分で融通の利かない、かつ納得がいかない状況に置かれたとき、人はじれったさとイライラを感じやすいものです。
しかし、状況を悲観するにはまだ早いのです!
このような時間のかかるルーティン業務こそ、もっとも自動化を始めやすい部分なのです!
例をもとに、ネットワーク管理の日々の業務を自動化できる状況と、その方法を見ていきましょう。
例えば、次のようなネットワーク管理者の状況を考えます。
Aさんは、社内の注文管理システムを管理する部署に所属しています。
その中でもAさんは、ネットワーク機器と、システムが稼働しているサーバー、サーバー内で稼働しているWebサーバーとアプリケーションのプロセスの死活を確認します。注文管理システムでは、連携企業からの注文が直接入る仕組みになっています。連携企業は複数あり、それぞれ休日が異なるため、Aさんの会社が休みの日にも注文が入ります。
Aさんと所属部署で、これまでの傾向からアクセス集中が見込まれる時間帯やシーズンのデータを基に、該当の期間には予め待機サーバーを起動させて、負荷分散をします。
この業務の例の場合、大きく分けて2つの業務をしていることが読み取れます。
- ネットワーク機器、サーバー、プロセスを常時監視している
- 定期的に待機サーバーの起動または停止等をしている
まずは、これらの定型業務を自動化する方法を確認しましょう。
ネットワーク機器・サーバー・プロセスの監視
これらは、ネットワーク監視、サーバー監視用のツールを用いることで簡単に自動化できます。
ネットワーク監視、サーバー監視製品には、無料のものから、数千万円するものまで、様々な種類があります。
その中でも、ネットワーク機器、サーバー、サーバーの中のプロセスの3種類の監視を満たすためには、
- ネットワーク機器、サーバーが同じコンソールで管理・監視できる
- サーバーの中のプロセスの起動状況を確認できる
ことが、製品選びの上で外せない条件になります。
また、ツールの導入の上でとんでもない工数がかかったり、ツールの保守で業務が増えたりしたら本末転倒です。
このため、製品は、導入が簡単であり、操作画面もわかりやすいものであることが望ましいと言えます。
待機サーバーの起動または停止
Aさんの例の場合、負荷が高くなるタイミングのデータを基にして手動で待機サーバーを起動、停止するとのことでした。
このような作業を自動化するには、ネットワーク監視製品が、定期的にサーバーの起動や再起動等の操作を定期的に実行できる機能を持っている必要があります。
決まっている動作を「毎週水曜日の午前6時」であったり「毎月25日の0時」など、細かく指定して定期的に実行できるものを選びましょう。
障害対応の自動化

先ほどのAさんの例の続きを考えます。
以前、Aさんの企業が休日の間に、注文管理システムの本体サーバーに異常が発生し、システムの一部が停止していたことがありました。
この時連携企業から受けた注文はシステムに入っておらず、のちに発覚し問題になったことがあります。
現在は、監視ツールで異常を検知したら電話での音声通知を受ける仕組みになっており、異常事態の場合は急いでサーバーのもとにかけつける態勢になっています。
休日に障害対応で駆けつけなければならないのは、とても大変です。
休日にまで障害対応に追われる前に、障害を予兆検知して予防できたら理想ですよね。
また、障害が発生しても、自動で復旧してくれるような態勢ができていたら、より良いかと思います。
この場合、ネットワーク管理を自動化する上で必要になることは、
- ネットワークの異常を、インパクトが大きくなる前の状態で検知すること
- 障害を検知した際に、適切な行動を自動でとれること
と考えられます。
予兆の検知
“予兆の検知”と聞くと、
「機械学習?マシンラーニング??」
「AI??」
といったように、難しく捉えられがちです。
しかし、上のような、サービスダウンが発生してしまうようなインパクトの大きい問題の場合は、その前から、サーバーのCPUやメモリの使用率高騰がずっと続いていたというようなことが多いです。
このため、予兆検知の第一歩として、ネットワーク機器のサーバーのリソースを確実に監視していくことから始めましょう。
これにより、大きな影響のある障害を減らしていくことができます。
障害検知時の対応自動化
「この時はこう」
「あの時はこれ」
という、状況に応じて色々な対応をとれるようにしようとすると、以下のようなものを思い浮かべませんか?
if(val1 != 1000){
val2++;
……
}else{
……
……
}そう、プログラムです。
予めプログラムで、状況を場合分けして、それに応じた対応を決めていたら、何でもできるかもしれません。
しかし、ネットワーク管理者はプログラマーではない場合が多いです。たとえプログラミングに詳しい担当者がいたとしても、プログラムの作成には、時間がかかるものです。
このことから、ネットワーク監視ツールでの自動化を考える場合、対応フローが、プログラムの必要なく簡単に作成できるものであることが望ましいです。
また、すでに独自のプログラムを持っている場合、それも同時に活かせるようなツールであれば、応用が利きます。
自動化後に確認すべき点
これまでの条件を満たすネットワーク監視ツールを導入したとして、ネットワーク監視や障害対応を自動化しても、丸投げにすべきではありません。
そもそもの障害原因の特定や、環境の改善のためには、
- いつ、どんな問題が発生したのか
- 自動化によって、いつ何が実行されたのか
を把握しておくことが大切です。
これにより、問題が発生する傾向や頻度をつかむことができます。
頻発している場合は、根本原因を特定して発生しないようにするなどの、環境の改善活動に繋げることができます。
OpManagerの場合
ご参考までに、当社のネットワーク統合監視ソフトの「ManageEngine OpManager」での、自動化例をご紹介します。
ネットワーク機器・サーバーの監視登録
OpManagerでは、複数ベンダーのネットワーク機器やサーバーを、細かい設定の必要がなく監視を開始することができます。
装置のディスカバリー(装置登録)から、監視したい機器があるネットワークの範囲を入力していくと…
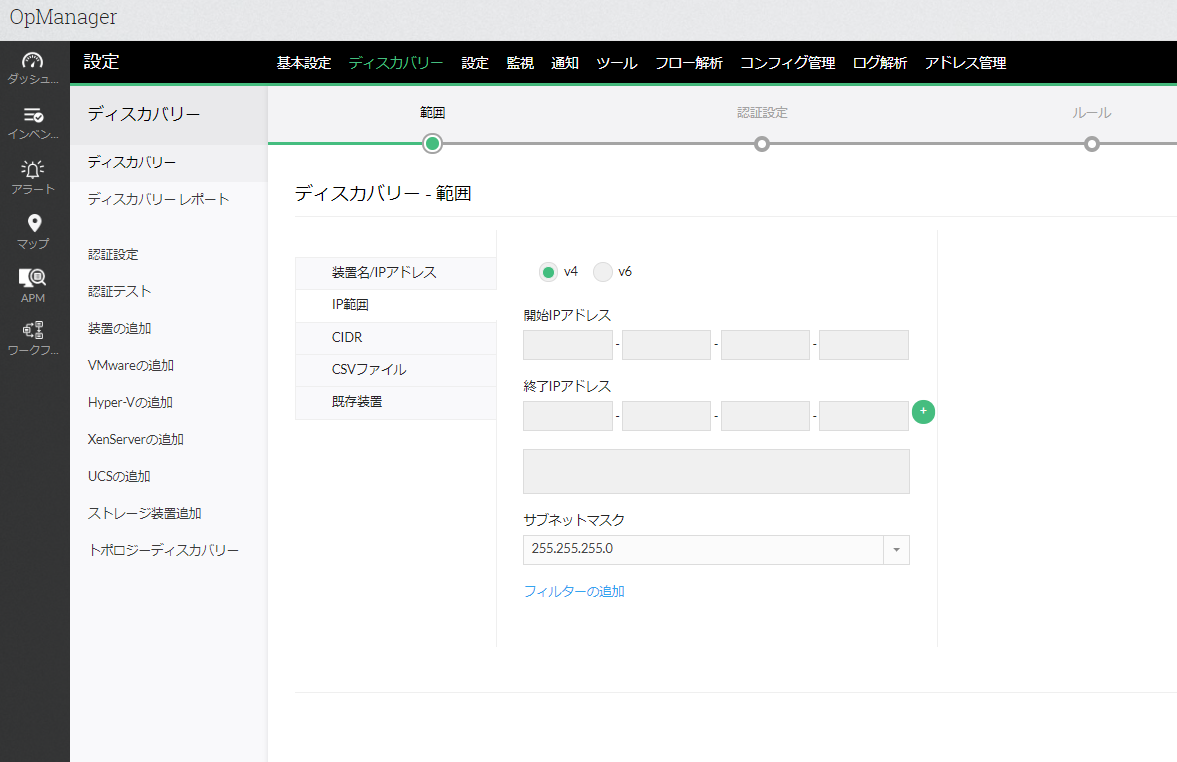
自動で機器ベンダーや機器タイプが識別され、監視が開始されます。
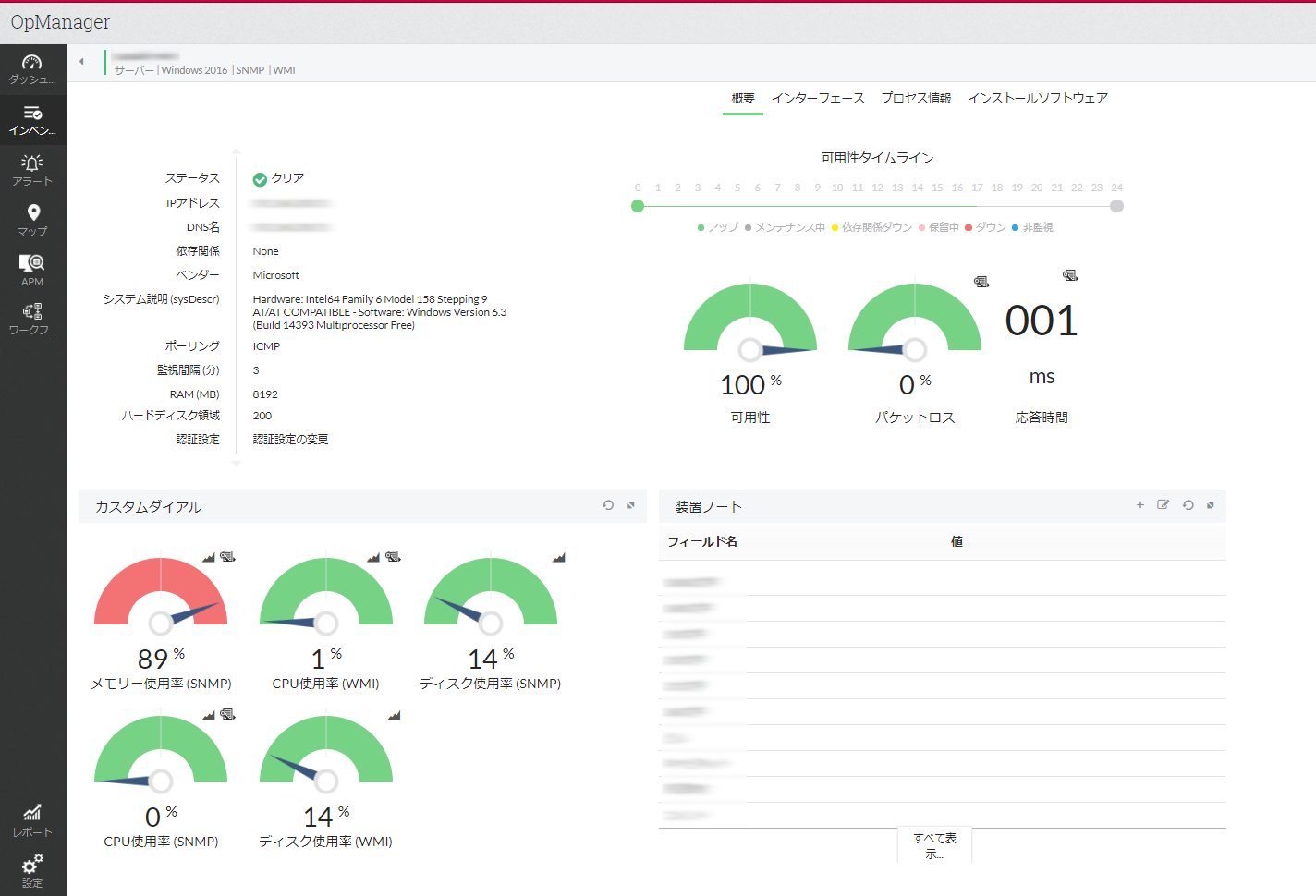
こうして、面倒な設定や手間がなく、ネットワーク機器やサーバー、プロセスの正常性を常に監視することができます。
2. 待機サーバーの起動または停止
定期的に何かを確認し、状況に応じて適切な行動をとるという業務も、OpManagerで自動化することができます。
OpManagerの「ITワークフロー」機能を使用して、
「○○の場合は●●」
「△△のときは▲▲」
というフローを組んで、自動で実行できるようにしましょう。
[ワークフロー]タブから[新規ワークフロー]をクリックすると……
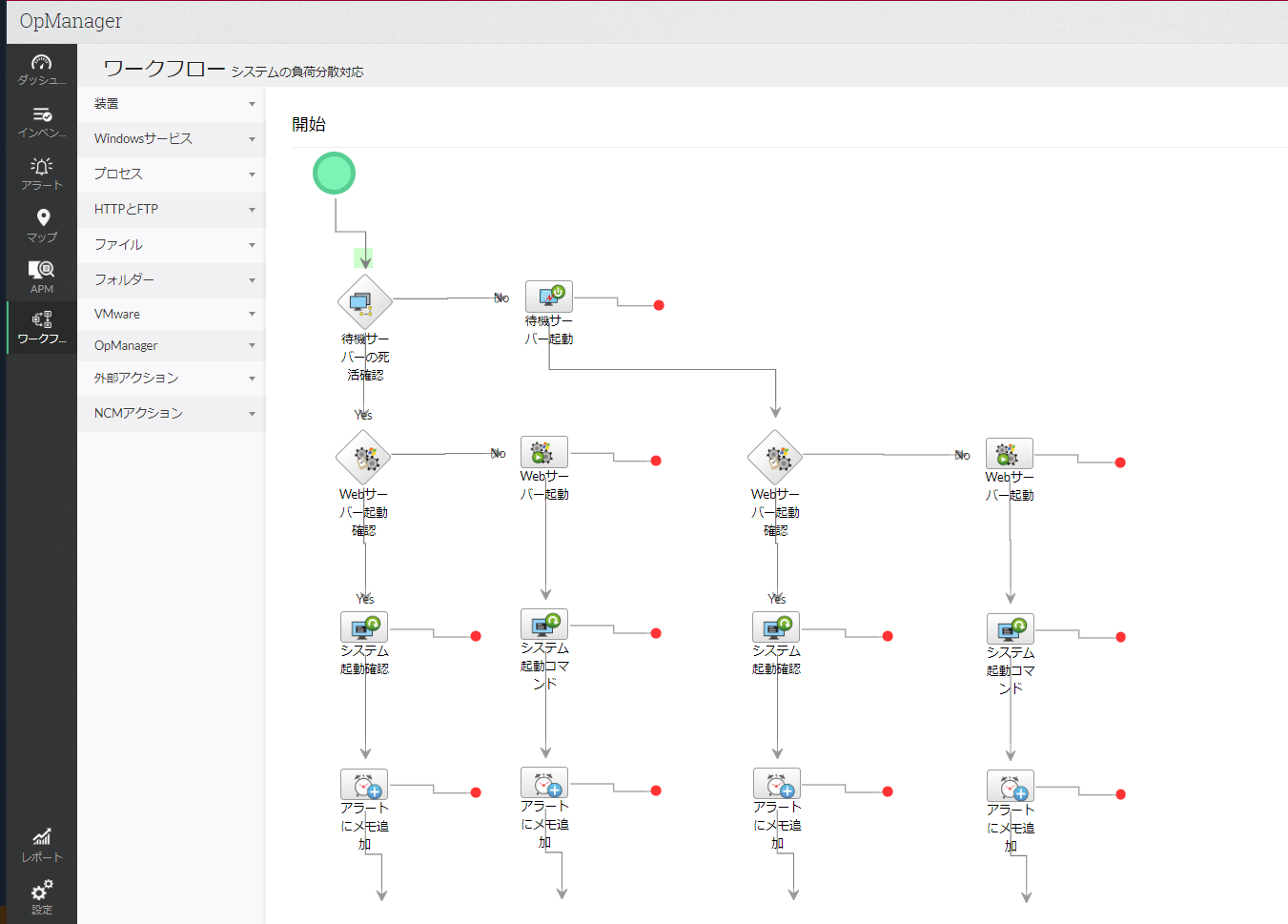
難しいプログラミングの必要がなく、アイコンのドラッグアンドドロップだけで簡単にワークフローができます。
上の例の場合、このワークフローが実行されたときに
- 待機サーバーの稼働確認
→稼働していなければサーバー起動 - Webサーバーの起動確認
→起動していなければ、Webサーバープロセスを起動 - ・・・・・
- ・・・・
というように、状況確認→実行という、普段の業務プロセスを、順々に実施し、状況に応じて適切な行動が実行されるように設定しています。
予兆検知
OpManagerで、障害が発生する前に自動で対処し、インパクトの大きい問題が発生する回数をできるだけ減らしましょう。
前段で、正常性監視のために追加したネットワーク機器、サーバーにしきい値を設定します。
これにより、いきなりダウンからの検知ではなく、CPU・メモリ使用率の高騰などのパフォーマンス低下の時点でキャッチすることができます。
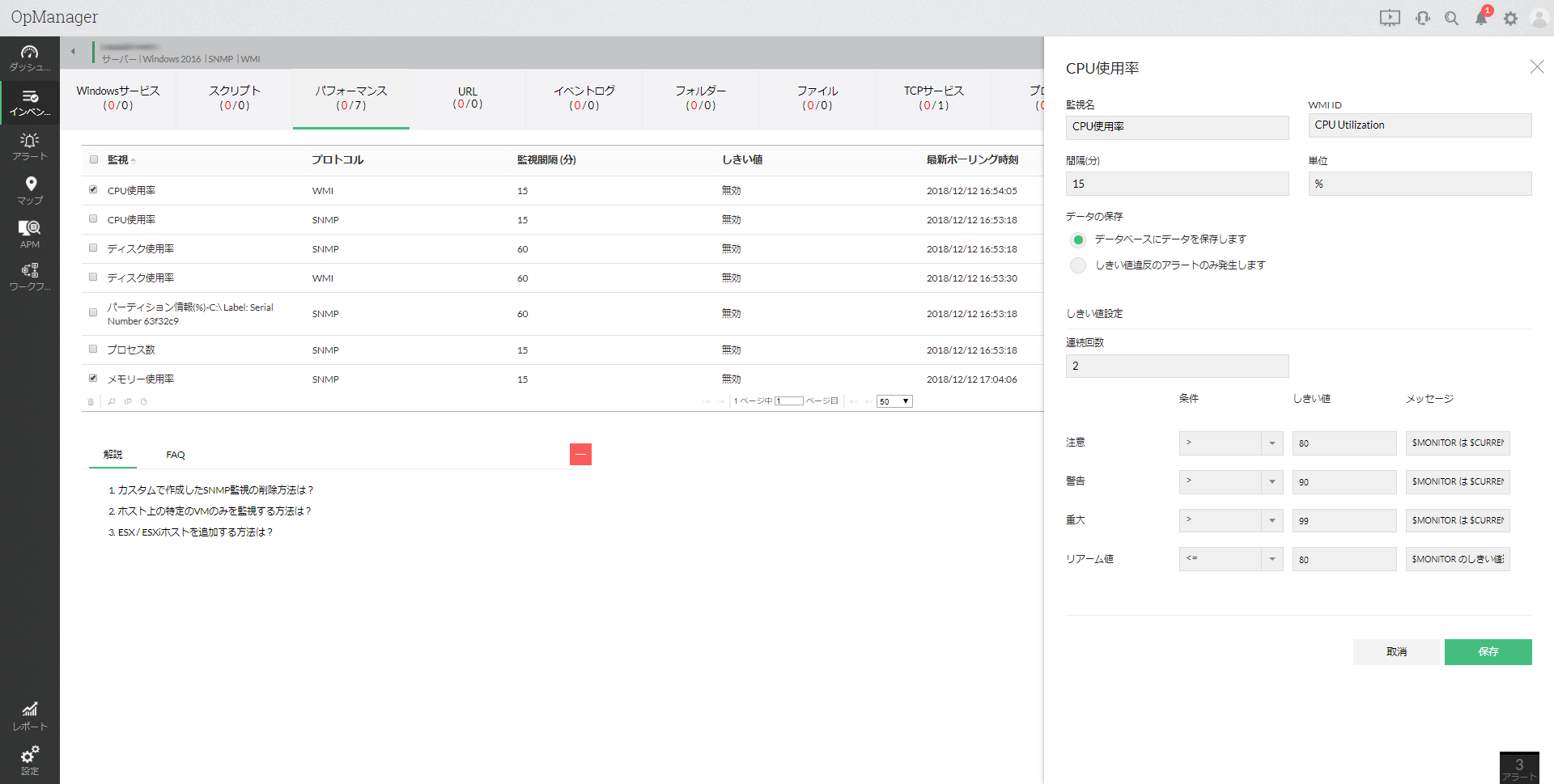
また、Aさんの例の場合は、注文管理システムが、もしもWebブラウザーからアクセスするタイプだったとしたら、
注文システムのURLの死活と応答時間も併せて監視追加するのもおすすめです。
そうすると、URLの応答時間の監視から、サーバーの処理速度低下を検知することができます。
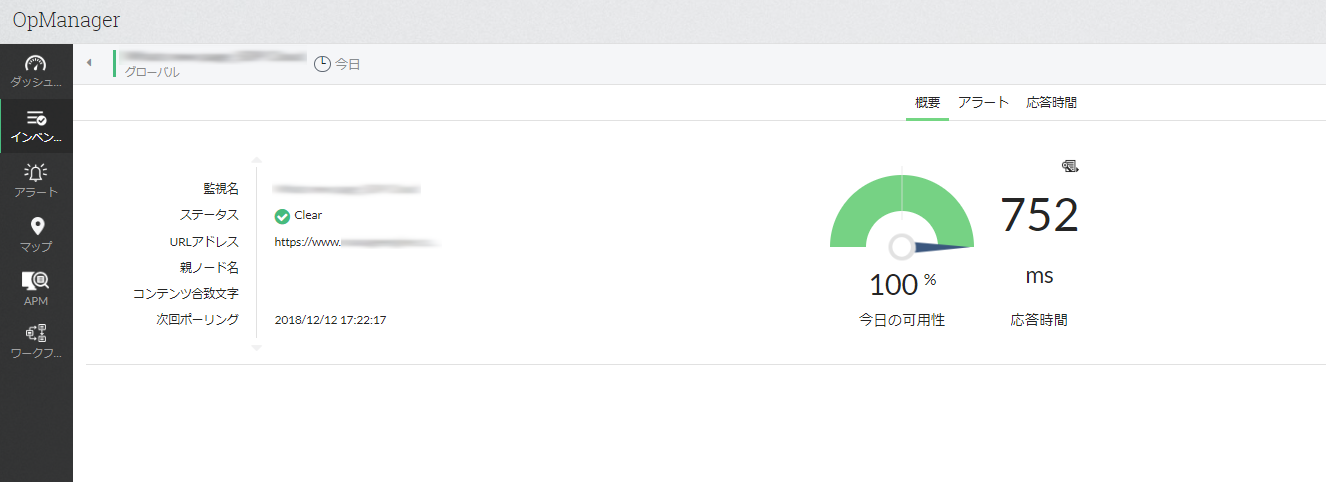
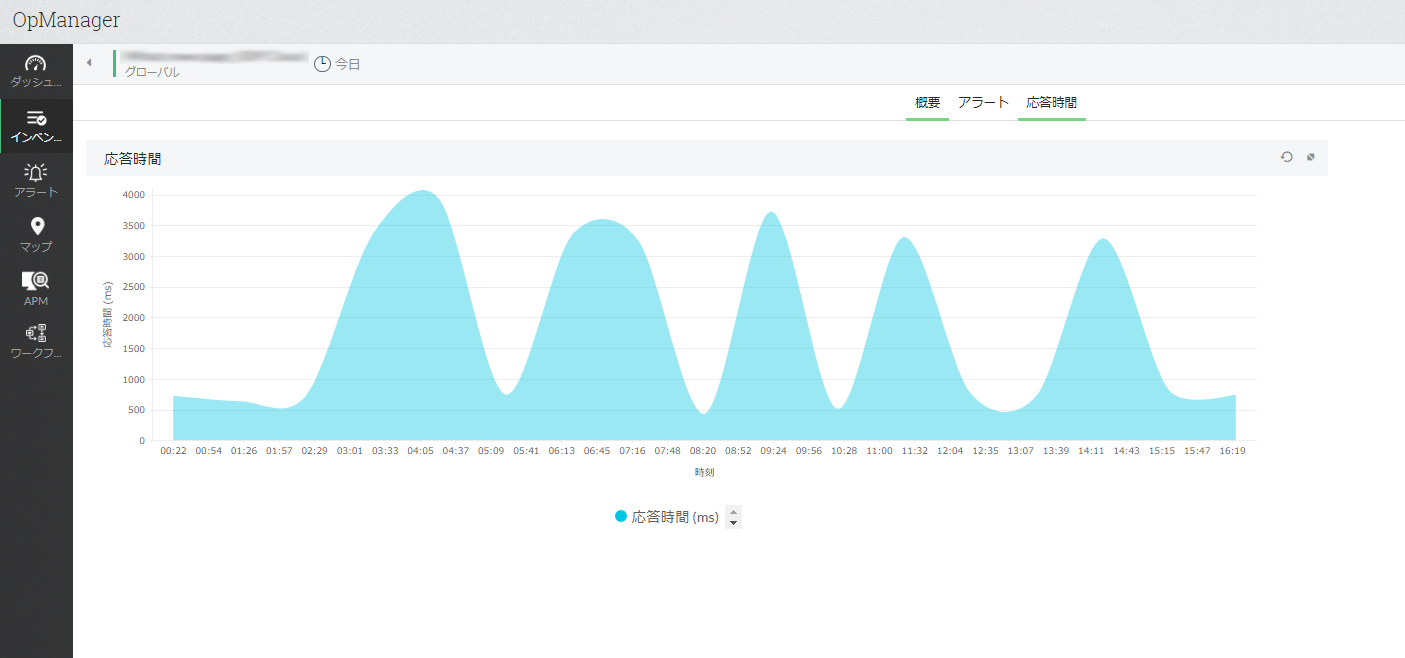
しきい値を違反したものは、アラート(障害情報)としてまとめて表示されます。アラート発生と同時に通知設定をしたり、またはプログラムを個別に実行する等の設定をすることができます。

また、上でご紹介したワークフローは、定期実行の他、OpManagerのアラート(障害情報)を基にしても実行することができます。
ワークフローを設定することで、障害情報からより細かい行動を設定して自動化することができます。
レポート
OpManagerでは、
- 「すべてのイベント」レポート
- 「ワークフローログ」レポート
を作成し、ネットワーク環境内で発生した問題と、実行されたワークフローの履歴を閲覧、レポートとして出力することが可能です。
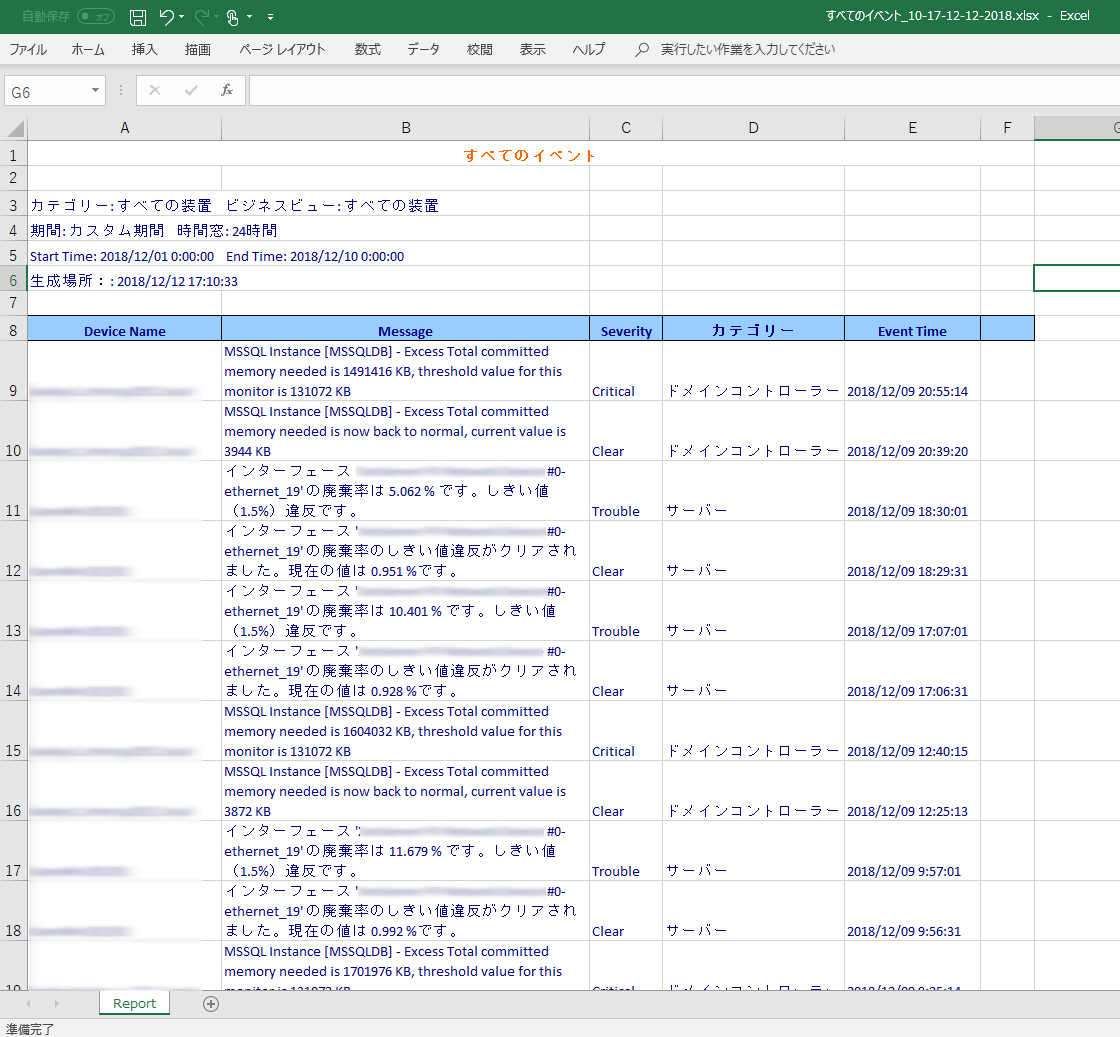
また、レポート機能では、監視対象サーバーやネットワーク機器の、休暇期間中のパフォーマンスも、あとからレポートとして簡単に図表化することができます。
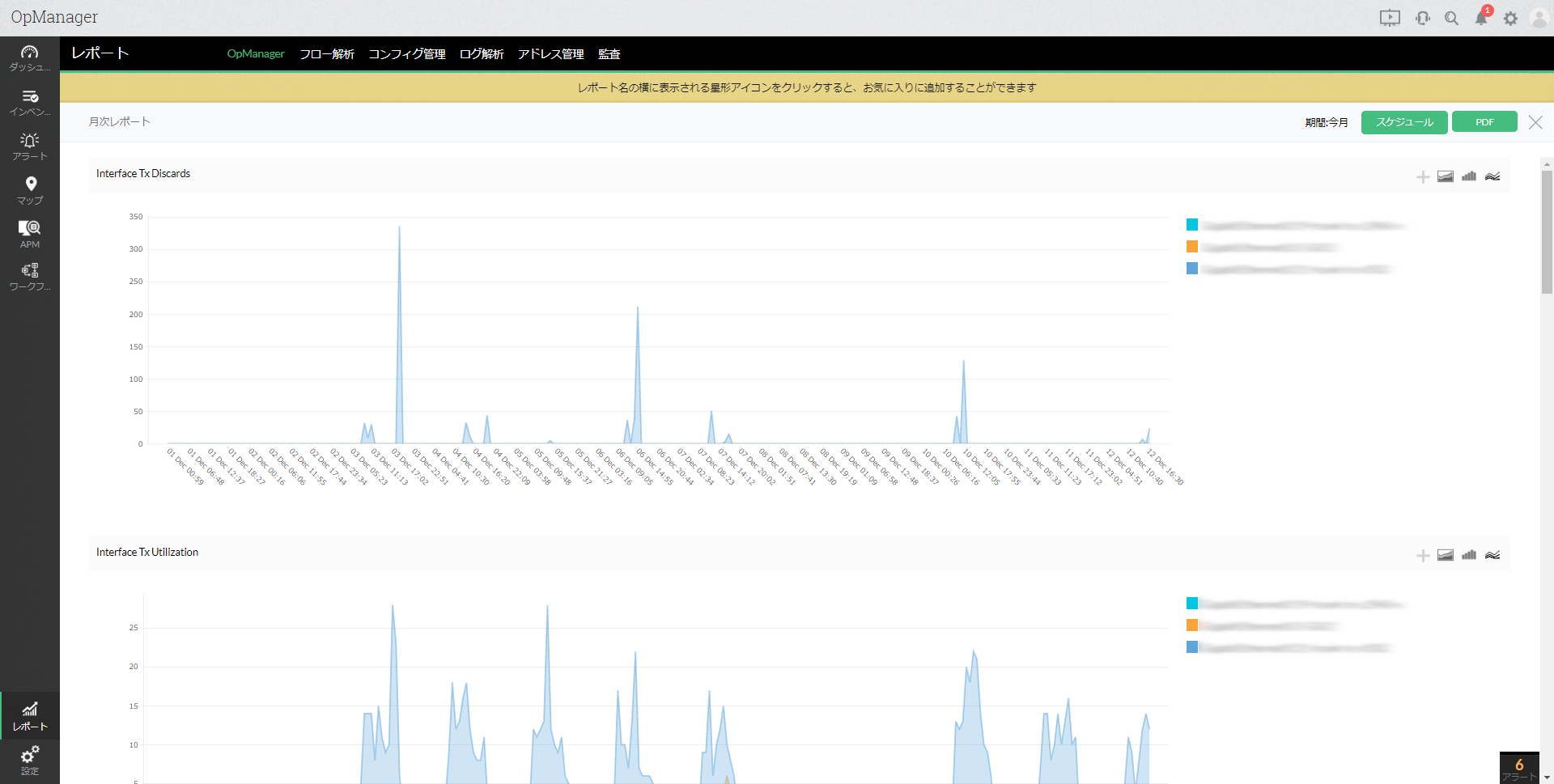
まとめ
ネットワークの管理を自動化するために必要なネットワーク管理・監視ツールの条件について、これまで考えてきました。
ネットワーク監視ツールの導入により…
- ネットワーク機器、サーバー、プロセスを常時監視
- 障害の予兆を検知
- 状況に応じて対応フローを自動実行
- 自動化後のレポート出力して分析
できることが大切!
「1分1秒でも停止したら困る!」というシステムは世の中にたくさんあります。
しかし、1人の人間は、1分1秒も休まずに働き続けることはできません。
ネットワーク管理ツールをうまく活用して自動化をしていくことで、世の中のネットワーク管理者が休暇を満喫できるようになれば幸いです。
関連リンク
OpManager公式ホームページ
OpManagerのダウンロードはこちら ※
OpManager製品概要資料のダウンロードはこちら
※永年無料版の利用をご希望の方は、30日間フル機能ご利用いただける「評価版」をダウンロードしてください。30日が過ぎると自動的に3デバイスまで監視可能の永年無料版となります。
▼▼ 関連記事 ▼▼
▶ 連載【ZabbixとOpManagerから学ぶ!統合監視の世界】
はじめに
01.Zabbixをインストールするまでの流れ
02.OpManagerをインストールするまでの流れ
03. 監視ソフトをインストールしたサーバー自身を監視する方法
ちょっと余談01. SNMP, WMI, CLIの違いについて
04.Zabbixで監視する機器を登録する方法
05.OpManagerで監視する機器を登録する方法
フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、以下のフィードバックフォームよりお気軽にお知らせください。