Reading Time: 1 minutes
こんにちは、ManageEngineエンジニアの園部です。
近年、社内サーバーやネットワークのリソースをクラウドに移行しようとしている企業も多いのではないでしょうか。
クラウド環境移行の計画の他、環境を管理する手段については考えていますか?
『クラウドのパフォーマンスは提供企業が管理するもの』――そう言い切って大丈夫でしょうか。
クラウドに置いた自社システムが遅くなったら、どのようにして原因切り分けをしますか?
この記事では、
★ サーバーやシステムの移行先として大人気のAWSを監視する必要性
また、Webシステムで一般的にボトルネックとなりやすいデータベースに焦点を当て
★ Amazon RDSとAmazon Auroraで監視すべきポイント
をご紹介します。
目次 |
AWS上のシステム監視の必要性
AWS上に構築したサービスやシステムの信頼性、可用性、パフォーマンスを維持するには、AWSクラウド監視ソリューションが必須であると言えます。
AWS上にシステムを配置している場合、障害が発生した場合に見るべき箇所は、
- システムの動作やパフォーマンスを確認
- Could Watchやサーバーのリソースを直接確認
- RDS等データベースとの連携を確認
- ネットワークの確認
など、見るべき箇所は多岐にわたります。各要素を別々に見ていくのはかなりの手間を要します。
システム障害のデバッグを簡単にするため、AWSリソースと、AWSリソース上で稼働するシステムを一元管理することが大切です。
Amazon RDSで監視すべき項目5選
Amazon RDSの特徴は、
- セキュリティ
- スケーラビリティ
- セットアップが簡単
- 高可用性
- 費用対効果
です。
RDSは、MySQL、PostgreSQL、MariaDB、Oracle Database、SQL Server、およびAmazon Auroraの、6つの主要なDBエンジンをサポートしています。
この柔軟さにより、あらゆるアプリケーションやツールがAmazon RDSとシームレスに動作するようになりました。
これらのデータベースを円滑に稼働させるために把握しておくべきメトリクスをご紹介します。
CPU使用率
RDSのCPU使用率は、RDSインスタンスに割り当てられたハードウェア内のCPUリソースの使用割合です。
アプリケーションは、CPU使用率の上限に達すると使用できなくなります。その理由は、各インスタンスのCPU使用率が一定量に制限されているからです。RDSインスタンス全体のCPU使用率を計測し、アプリケーションが過負荷か低負荷かを判断し、制御できるようにしましょう。
メモリー消費量
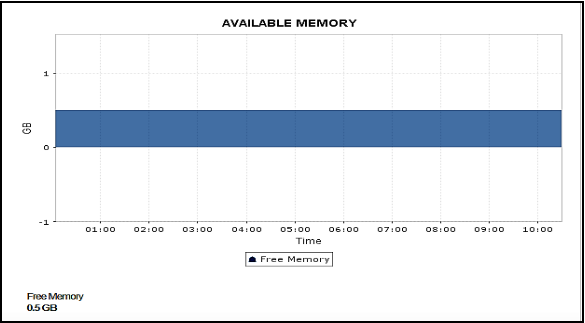
メモリー使用のパターン変化も、CPUと併せて把握しましょう。
データベースインスタンスでストレージ領域が不足すると、データの損失やアプリケーションのボトルネックにつながる可能性があります。
ストレージ容量の限界に近づいたときに、データベースインスタンスを拡張できます。アプリケーションからの予期しない要求に対応するため、ストレージとメモリーにバッファを確保することが重要と言えます。
空きメモリー値が常に低い値を示す場合は、データベースがメモリーー不足である可能性があります。パフォーマンスの問題が発生した場合、または空きメモリーがない場合は、より大きなインスタンスにアップグレードする必要があります。
最適なRDS監視のために、DBインスタンスにメモリーの制約がないことを常に確認しましょう。
ネットワークトラフィック
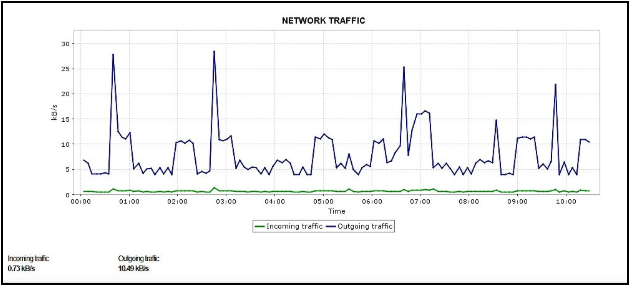
ネットワークトラフィックはスループットに大きく影響を及ぼします。受信スループットや送信スループットなどの重要項目を把握しましょう。
CPU、メモリー、ストレージと同様に、各インスタンスには一定のネットワーク帯域幅を割り当てる必要があります。
DBインスタンスに割り当てられるネットワーク帯域幅は、インスタンスのサイズによって決まります。小さいインスタンスほど帯域幅が低く、大きいインスタンスほど帯域幅が広くなります。
IOPS
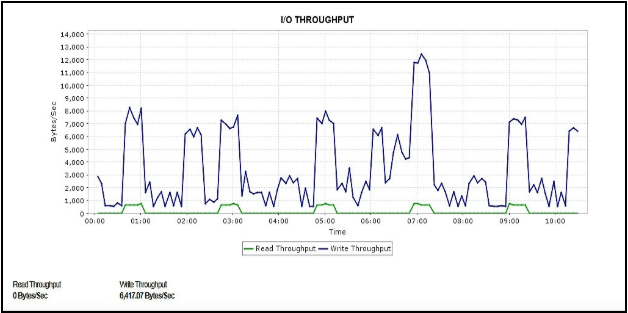
IOPS(I/O per Second)とは、ディスクが1秒毎に処理するI/Oアクセス数です。問い合わせ待機時間を取得して、ディスクレベルでのI/O操作にかかる時間を測定します。IOPSの期待値を維持するには、ベースライン値を設定し、その値と結果が異なるかどうかを調べます。
- 読み込み(リード)IOPS:読み込みIOPSが急激に上昇した場合は、クエリ実行が暴走している可能性があります。
- 書き込み(ライト)IOPS:書き込みIOPSが急激に上昇した場合は、データが大幅に変更された可能性があります。
入出力操作キューを計測することによって、ストレージボリュームの設定を、読み込みリクエストと書き込みリクエスト量に合わせることができます。
アプリケーションのパフォーマンスを最適化するには、読み込み・書き込み動作を最小限に抑えます。割り当てられたメモリーに標準的な作業セットが収まるようにしましょう。
レイテンシー
待機時間の測定は、DBのパフォーマンスに影響を与えるリソースの制約の特定と調査に役立ちます。RDS環境で実行しているアプリケーションの読み取りまたは書き込みが遅い場合は、トランザクションの待機時間を監視します。
Aurora DBで監視すべき項目4選

Amazon Auroraは複数のプライマリDBインスタンスで構成されます。DBクラスタの複数のAvailability Zone(AZ)に、最大15のAuroraレプリカを作成することができます。
レプリカには、次の3つの個別のエンドポイントが割り当てられます:
- クラスタエンドポイント:そのDBクラスタのプライマリDBインスタンスに接続します。
- インスタンスエンドポイント:Auroraクラスタ内の特定のDBインスタンスに接続します。DBクラスタ内の各DBインスタンスは、インスタンスタイプに関係なく、固有のインスタンスエンドポイントを持ちます。
- 読み込みエンドポイント:そのDBクラスタで使用可能なAuroraレプリカの1つに接続します。
リードレプリカ

Auroraレプリカは、クラスタボリュームの読み取り操作専用です。
遅延が大きい場合は、レプリカからの読み取り操作が現在のデータを処理していないことを示します。
書き込み操作は、プライマリインスタンスによって管理されます。データがAuroraに書き込まれると、Auroraはすべてのデータ・コピーにデータを書き込みます。プライマリ・インスタンスの書き込み更新が完了すると、Auroraレプリカは、100ミリ秒未満の最小限のレプリカ・ラグで、クエリ結果として同じデータを返します。レプリカの遅延は、DBの変化率によって異なります。大量の書き込み処理を行うと、レプリカが遅延する可能性があります。
プライマリインスタンスに障害が発生した場合は、レプリカがプライマリインスタンスとして昇格され、高可用性が維持されます。フェイルオーバーが発生し、Auroraレプリカが存在しない場合、DBインスタンスが障害イベントからリカバリするのにかかる時間にかかわらず、DBクラスタは使用できません。
ボリュームIOPS
この項目は、5分ごとのクラスタ・ボリュームからの読み取りまたは書き込み操作の平均量を測定します。
ボリューム読み取りIOPSの値は小さく、安定している必要があります。
読み取りI/Oで異常なスパイクが発生した場合は、DBインスタンスに原因がある可能性があります。調べて原因を特定し、システム遅延のボトルネックを減らしましょう。
キャッシュバッファヒット率
この項目は、リクエストされたクエリがメモリーに格納されているデータで処理される割合を意味します。これを監視すると、メモリーから処理されるデータ量を詳細に把握できます。
キャッシュバッファヒット率が高い場合は、ディスクにアクセスしてデータを取得する必要がないことを示します。この値が小さい場合は、DBインスタンス内の問合せがディスクに頻繁に送信されていることを示します。
メモリーとディスクの処理速度を比較すると、メモリーからのデータ処理の方が高速です。キャッシュバッファヒット率を維持できるようにシステムを見直しましょう。
クエリのパフォーマンスとスループット
クエリのスループットを追跡して、DB操作を把握しましょう。 すべてのデータ定義言語(DDL)リクエストのスループットと待機時間を測定することで、クエリキャッシュからクエリが提供されるかどうかに関係なく、クエリパフォーマンスを測定します。クエリボリュームに突然の変更が発生した場合にアラートを設定して、パフォーマンスのボトルネックを事前に検知できることが望ましいです。
まとめ
Amazon RDSやAurora DBで監視すべき項目についてご紹介しました。
AWSクラウドにこれからシステムを移行する方、RDSの監視を始めたばかりの方は、これらの項目の監視から始めてみてください。
安定稼働や高速化を実現するための第一歩として、この記事が役に立ちましたら幸いです。
RDSの場合:
- CPU、メモリー、ネットワークトラフィックを監視し、土台の安定性を確保しましょう!
- IOPSとレイテンシーを把握し、データベースのパフォーマンスを安定させましょう!
Amazon Auroraの場合:
- レプリカのステータスを把握しましょう!
- ボリュームのIOPSを把握し、インスタンスに問題がないことを確認しましょう!
- キャッシュバッファヒット率、クエリのパフォーマンスを把握し、正常な状態、異常な状態を見分けられるようにしましょう!
※ なお、監視すべきポイントの紹介で使用したグラフイメージは、ManageEngineのアプリケーション性能管理ソフト『Applications Manager』の画面スクリーンショットを使用しています。
これらのスクリーンショットのグラフは、特別な作りこみが必要なく、監視情報の入力で簡単に作成できます。
AWS上のWebシステムのパフォーマンス監視要件でお困りの際には、ぜひApplications Managerをご検討ください!
▼▼ Webシステムの統合監視なら、ManageEngine Applications Manager ▼▼
Applications Manager 公式ホームページ
Applications Managerのダウンロードはこちら ※
Applications Manager製品概要資料のダウンロードはこちら
※永年無料版の利用をご希望の方は、30日間フル機能ご利用いただける「評価版」をダウンロードしてください。
30日が過ぎると自動的に5モニターまで監視可能の永年無料版となります。


フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、以下のフィードバックフォームよりお気軽にお知らせください。