Reading Time: 1 minutes
2014年7月24日(木)、秋葉原においてゾーホージャパン主催で
「システム運用の6大課題を解決できるサーバ・ネットワーク監視セミナー」を開催しました。
ご来場いただきました皆様、誠にありがとうございます!
会場は、さいきんよく利用させていただいている富士ソフトアキバプラザです。
秋葉原駅(中央改札口)から徒歩5分と、便利な立地です。

今回のセミナーのアジェンダは次のとおりで3セッションでした。
【1】予兆監視とトラブルシューティングの効率化
【2】システム運用の6つの課題を解決する方法
~ManageEngine OpManagerのご紹介~
【3】デモンストレーションと導入事例
本ブログでは初披露の講演だったセッション1について紹介します!
~~~~~~~~~~~~~~~~~~~~~~~~~
【1】予兆監視とトラブルシューティングの効率化
~~~~~~~~~~~~~~~~~~~~~~~~~
セッション1では、以下のような内容を紹介しました。
①システム障害の影響の見積もり方
②システム障害の影響を最少化するサーバ・ネットワーク監視とは
③事後対応から事前対応に切り替える予兆監視
④自動化によるトラブルシューティングの効率化
講演では、参加者に次のような質問についても考えていただきました。
Question 1: ネットワークのダウンタイムによる損失は年間どれくらいか把握していますか?
Question 2: システム障害を予防するためにどのようなことをしていますか?
Question 3: 障害発生後、それを拡大しないためにどのようなことに気をつけていますか?
みなさん、真剣に考えていただいていました!
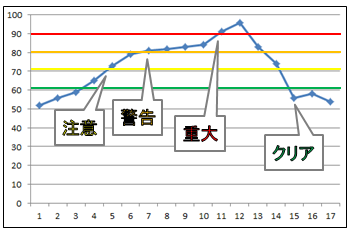
③予兆監視では、しきい値を利用した性能監視により、
障害につながる情報を早い段階でキャッチすることの重要性についてお話ししました。
ユーザからクレームがあってから障害対応するなどの事後対応を事前対応に
シフトしていくという考え方です。
OpManagerでは3段階のしきい値(注意/警告/重大)を設定でき、段階的にアラームを発生させます。
④トラブルシューティングの効率化では、万が一障害が発生してしまっても、
繰り返し行っている作業を事前に把握しておき、それを自動化することの重要性をお話ししました。
こういうジョブの自動化にOpManagerのワークフロー機能が有効活用できることを紹介しました。
ワークフロー機能
http://www.manageengine.jp/products/OpManager/it-workflow-automation.html
ワークフローでは、ジョブを実行するために次のような2種類のトリガーを利用できます。
1. アラームが発生したときにワークフローを実行
2. 定期的にワークフローを実行
講演を聞いていただいた方は、システム障害による損失の計算方法や
障害監視をレベルアップする考え方・ヒントなど、
手ごたえを感じていただいたのではないでしょうか!
(複数の参加者のアンケートにこのようなコメントがあり、嬉しい限りです!)
次回のセミナーは9月3日(水)@東京国際フォーラム(有楽町)です!
http://www.manageengine.jp/news/event_20140903.html
このブログを読んでくれたあなたの来場をお待ちしています!!
フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、以下のフィードバックフォームよりお気軽にお知らせください。